系统
- 系统
- 教程
- 软件
- 安卓
时间:2020-09-22 来源:u小马 访问:次
后羿采集器是一款专业实用的的网页数据采集器,功能强大,操作简单,是为广大无编程基础的从业者量身打造的一款产品。它由原Google技术团队倾力打造,其规则配置简单,采集功能强大,能够支持电商类、生活服务类、社交媒体、新闻论坛等不同类型的网站。今天小编就来教大家后羿采集器自定义采集百度搜索结果数据的方法教程,希望大家会喜欢。
后羿采集器自定义采集百度搜索结果数据的方法:
步骤1:创建采集任务
1)启动后羿采集器,进入主界面,选择自定义采集并点击创建任务按钮创建"自定义采集任务"
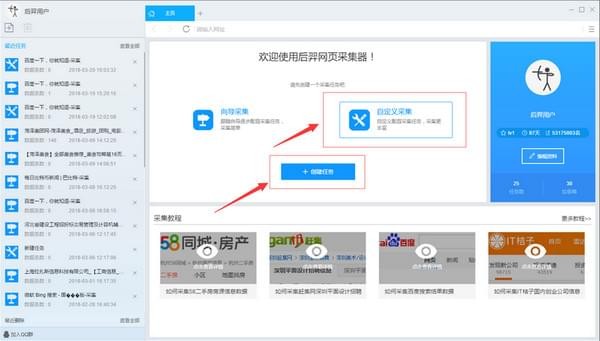
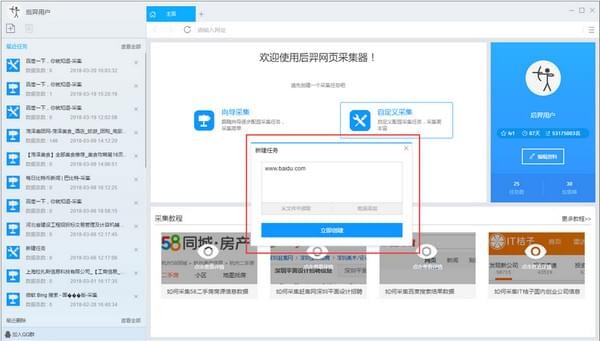
2)输入百度搜索的URL,包括三种方式
1、手动输入:在输入框中直接输入URL,多个URL时须要换行分割
2、点击从文件中读取方式:用户选择一个存放URL的文件,文件中可以有多个URL地址,地址须要换行分割。
3、批量添加方式:通过添加并调整地址参数生成多个有规律的地址
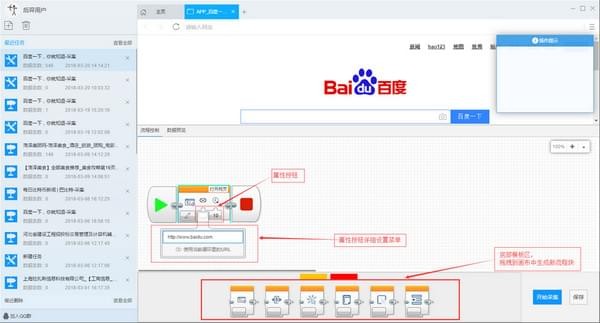
步骤2:自定义采集流程
1)点击创建后自动打开第一个URL进而进入自定义设置页面,默认已经创建了开始、打开网页、结束的流程块。底部模板区用于拖拽到画布中生成新的流程块;点击打开网页中的属性按钮,可修改打开的网址
2)添加输入文字流程块:在底部模板区中拖拽输入文字块到打开网页块后面附近,当出现阴影区域的时候可以松开鼠标,此时会自动连接,添加完成
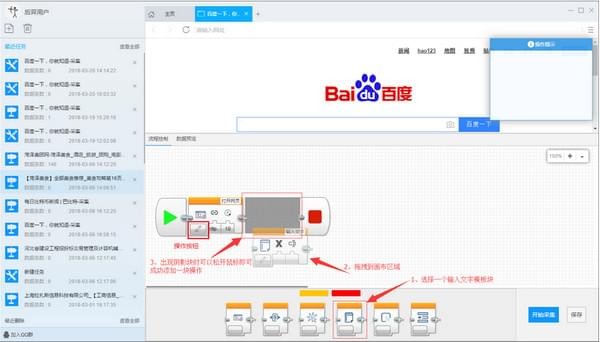
3)生成完整流程图:仿照上面添加输入文字流程块的拖拽流程添加新块:如下图所示:
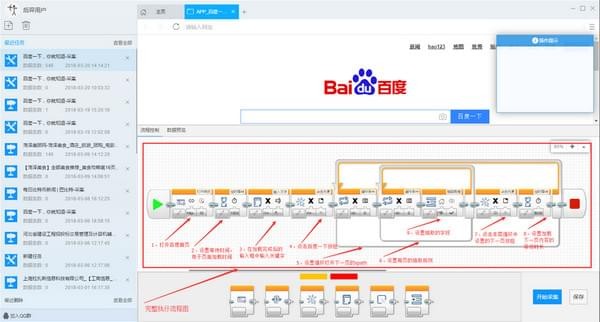
关键步骤块设置介绍
步骤2:定时等待用于等待前面打开网页完成
步骤3:点击输入框Xpath属性按钮,在属性菜单中点击图标进行点选网页中的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
步骤4:用于设置点击开始搜索按钮,点击元素的xpath属性按钮,在菜单中点击点选图标,然后点击网页中的百度一下按钮即可。
步骤5:用于设置循环加载下一列表页。在循环块内部的循环条件块中设置详细条件,此处点击操作按钮,选择单个元素,然后在属性菜单中点击元素的xpath属性按钮,同上进行点选网页中的下一页按钮。循环次数属性按钮可默认为0,即不限制点击下一页的次数。
步骤6:用于设置循环抽取列表页中的数据。在循环块内部的循环条件块中设置详细条件,此处点击操作按钮,选择不固定元素列表,然后在属性菜单中点击元素的xpath属性按钮,然后在网页中连续点选两次抽取第一块和第二块元素。循环次数属性按钮可默认为0,即不限制列表中收取字段的数量。
步骤7:用于执行点击下一页按钮操作,点击元素xpath属性按钮,选择使用当前循环中元素的xpath选项。
步骤8:同理用于设置网页加载等待时间。
步骤9:用于设置在列表页抽取的字段规则,点击属性按钮中使用循环中的元素按钮,选择使用循环中的元素选项。点击元素模板属性按钮在字段表格中点击加减进行添加删除字段,添加字段使用点选操作,即点击加号后鼠标移动到网页元素上点击选择。
4)点击开始采集,启动采集
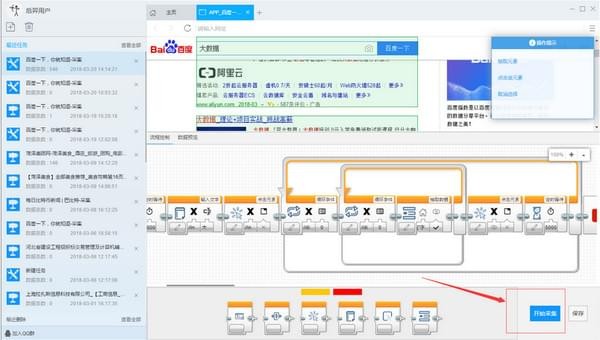
步骤3:数据采集及导出
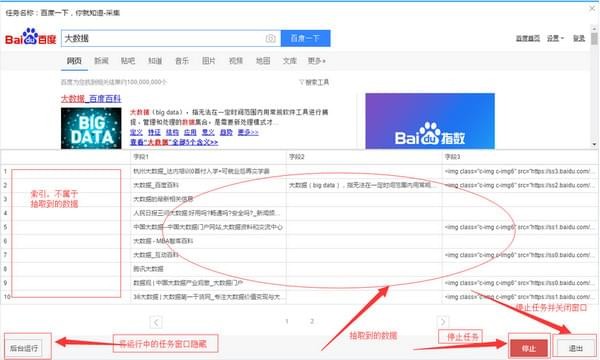
1)采集任务运行中
2)采集完成后,选择“导出数据”可以把数据都导出到本地文件
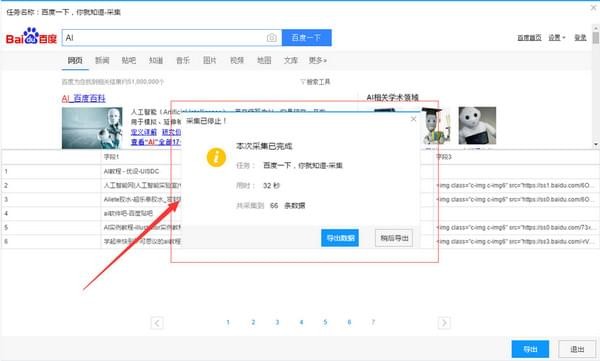
3)选择“导出方式”,将采集好的数据导出,这里可以选择excel作为导出为格式
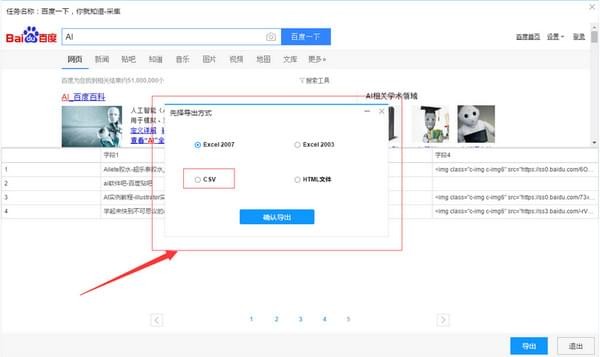
4)采集数据导出后如下图
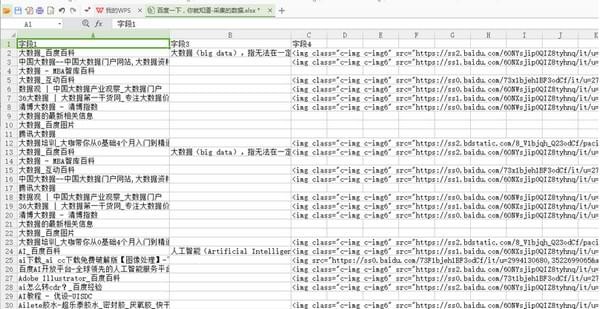
以上介绍的内容就是关于后羿采集器自定义采集百度搜索结果数据的具体方法,不知道大家学会了没有,如果你也遇到了这样的问题的话可以按照小编的方法自己尝试一下,希望可以帮助大家解决问题,谢谢!!!想要了解更多的软件教程请关注Win10镜像官网~~~~



本站发布的Win10镜像与软件仅为个人测试使用,请在下载后24小时内删除,不得用于任何商业用途,请支持购买 微软原版 Msdn Win10 iso镜像!如侵犯到您的权益,请及时通知我们。
Copyright © 2019 u小马 版权所有 蜀ICP备20004165号-1
 川公网安备 51130402000044号
川公网安备 51130402000044号