系统
- 系统
- 教程
- 软件
- 安卓
时间:2017-05-13 来源:u小马 访问:次
由于即便是同一款处理器跑两次SEPC2006的分值也有有少许上下浮动。因而可以推断出兆芯的C款处理器C4600和兆芯的A款处理器VIA Nano C4350AL采用了相同的微架构,或者说以赛亚和以赛亚2的差异微乎其微,以至于在性能上处于原地踏步状态。
除了前端总线的频率和工艺的差别,各种微结构的参数都没有任何变化,也就是说“以赛亚2”和“以赛亚”其实是同一个东西,或者说修改的地方微乎其微,以至于在性能上处于原地踏步状态,修改可以忽略不计。
必须说明是是实验中,C4600的定点性能比C4350al略高一些,主要原因是C4600的前端总线的频率提高了,C4600浮点性能反而略有下降,主要原因是由于其采用的SSE4.2指令集没有硬件的逻辑实现,并且DDR3-1600带宽的提升反而弥补不了延迟的略微增加,以至于浮点性能下降。
兆芯C4600和VIA以赛亚的短板
Centaur公司设计的以赛亚在当时是立足差异化竞争的产物,以赛亚也是一个轻量级的架子,虽然在2009年的时候这个设计还是挺不错的。但随着技术的进步,以赛亚在今天就有点不够看了,面对ARM Cortex A57/A72/A73就难以招架了。下面简单介绍一下兆芯C4600和VIA以赛亚的短板:
短板一:没有对最新的指令系统在微结构和硬件上进行改动
根据VIA官方资料,VIA Nano只支持到SSE4.1指令集系统,至于原因只要回溯Intel指令集系统的发展历史就明了了:MMX(1996), SSE(1999), SSE2(2001), SSE3(2004),SSSE3(2006), SSE4.1(2006)SSE4.2(2007), AES, AVX(2011), F16C(2009), ACE, PCLMUL(2010), VMX, BMI1, BMI2, AVX2(2013)。
正是因为历史原因以及Intel对外的X86授权因素,当时的VIA公司没有拿到Intel最新指令集系统的授权,所以2009年的Nano处理器最高支持到SSE4.1。
相比之下,VIA QuadCore C4650和兆芯C4600处理器支持后续的SSE4.2和最新的AVX和AVX2等指令集系统。
对于VIA QuadCore C4650和兆芯C4600支持最新的AVX和AVX2等指令集系统,可能的原因是VIA已经买到了Intel公司最新指令集系统的授权。不过VIA如何将指令集授权转让给兆芯,这个问题无论是Intel,还是VIA、兆芯都没有任何公开声明。
诚然,这个不是本文关注的重点。本文关注的是缘何增加了AVX和AVX2等指令集系统C4600的性能反而下降了。
Intel和AMD的CPU在使用了最新的256位的AVX/AVX2向量指令集后,性能有所提高——Intel和AMD处理器采用向量指令(128位和256位),INT2006的性能平均可以提高5%,FP2006的性能平均可以提高16-18%。而从128位的SSE,增加到256位的AVX/AVX2指令,INT2006的性能可以提高2-3%,FP2006的性能可以提高6-8%。
必须说明的是,采用向量指令提高性能的前提是处理器的访存通路能供应上足够宽的数据,如Haswell为了支持256位的AVX/AVX,采用了3个访存的端口,同时支持2个256位的load操作和1个256位的store操作。
与Intel和AMD的CPU相反,C4600处理器兼容了Intel最新的256位向量指令AVX/AVX2等(不支持乘加FMA指令)。在编译时打开了AVX2, AVX, bmi等最新指令集编译选项,但编译出来的程序实测性能反而下降。具体成绩为图15。
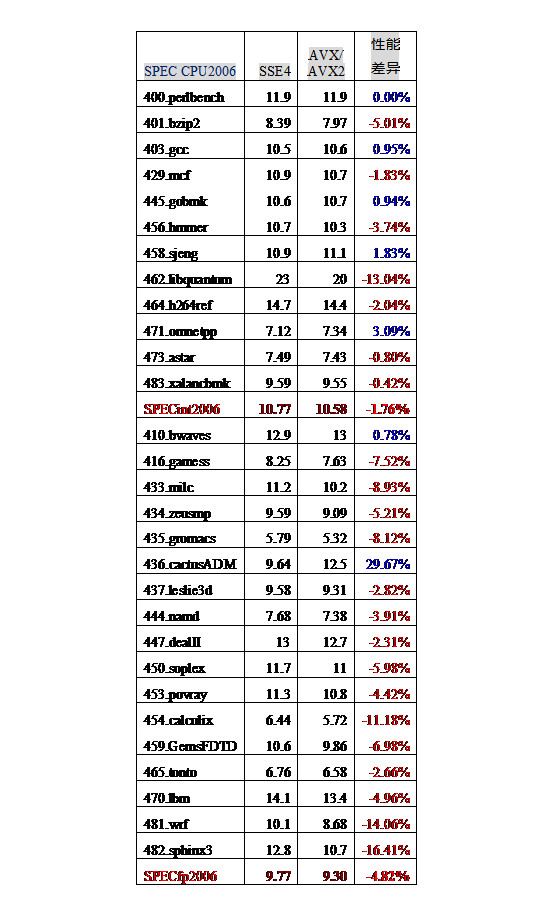
从图中可以看出,采用最新的指令集系统,对于大部分CPU2006的程序,其性能反而下降了。对于INT2006,几何平均的性能下降了1.76%,如401.bzip2下降了5.01%,456.hmmer下降了3.74%,462.libquantum下降了13.04%;对于FP2006,几何平均的性能下降了4.82%。416.games下降了7.52%,433.milc下降了8.93%,435.gromacs下降了8.12%,454.calculix下降了11.18%,454.calculix下降了14.06%,459.GemsFDTD下降了6.98%,482.sphinx3下降了16.41%。而这些程序正好是易于被向量化的程序,其采用了256位的AVX指令。例如459.GemsFDTD中256位的Packed Double动态指令数占到16.53%。
为什么采用新型的指令集系统,SPEC CPU2006程序性能反而有所下降呢?很可能是兆芯C4600处理器保留了Centaur公司的原始设计,没有对最新的指令系统在微结构和硬件上进行改动,也就是在微结构上除了指令译码部分,在数据通路和访存通路上没有变化。而这也作证了之前提到的:以赛亚2和以赛亚其实是同一个东西,或者说修改的地方微乎其微。
首先来看处理器在指令译码部分怎么支持最新的指令集系统,在当前的CISC指令集系统的实现都是将外部CISC指令翻译为内部的类RISC,即uops,通常一条CISC指令可以在内部被翻译为1-3条内部的uops指令。uops指令在“以赛亚”被称为micro-ops,见VIA Isaiah Architectural文章中“microcode subsystem”,“以赛亚”架构中的微码子系统(microcode subsystem)包括24K微指令加上一个强大的打补丁(patch)的功能,使得微码能被更新,每个ROM中的微码指令被翻译为最多3条融合的微操作(fused micro-ops)。可以看出“以赛亚”架构仍然在沿用X86处理器早期的部分复杂X86指令微码实现的方式,如果要支持新的如AVX的指令,就可以通过更新微码的方式来实现,再通过微码指令转换为内部的微操作指令实现。
第二,256位寄存器的实现,既然要支持AVX指令,需要实现256位的体系结构可见的寄存器和256位的重命名物理寄存器,我们猜测其内部实现为仅实现了体系结构可见的寄存器,而没有实现256位的重命名物理寄存器,这不会增加太多的开销。在数据通路和访存通路的实现上,在内部很可能是将256位的向量指令拆分为多条128位的类SSE指令实现的,这种方法在第一代AMD的推土机实现256位的AVX指令和第一代的K8实现128位的SSE指令也是这么做的,通过内部拆分在数据通路上支持新的指令集系统,但是这样做的结果是,新的指令系统对性能不但没有好处,反而会有性能的下降,因为数据通路和访存通路根本就没有实现更宽的设计,就好比本身很窄的马路,可以通过2个车道,这时候同时来4辆车,这4辆车就得排成两排,顺序通过。另外,更宽的向量操作导致其架构的访存和供数能力跟不上,这也造成了新指令集有时性能下降的原因。
短板二:前端总线设计和带宽
限制兆芯C4600芯片的一大瓶颈是Centaur公司延续了其前端总线(VIA V4 bus)的设计,而且没有将内存控制器集成到处理器上。
前端总线(front-side bus,FSB)是早期Intel芯片的计算机通信的接口,和AMD公司的EV6类似,其连接CPU和北桥芯片,内存控制器通常集成在北桥中。PCI,AGP等各种设备以及内存都是通过北桥和CPU进行通讯。
前端总线出现在1995-2006,用于Intel的Atom,Celeron,Pentium,Core2芯片以及早期的Xeon芯片,其很快被现代处理器中AMD的HT(HyperTransport)和Intel的QPI(QuickPath Interconnect)以及DMI(Direct Media Interface)所取代。
前端总线为64位,8个字节,每拍能传输4次。前端总线的速度是当时计算机系统一个重要的衡量指标,当前,前端总线最高的频率为333~400MHz,每个周期能进行4次传输。由于设计的缺陷,前端总线的频率没法得到进一步提升。假设前端总线的实际频率为333MHz,也就是通常厂家说的1333MHz,其峰值理论带宽为10.65GB/s,即8 bytes/transfer × 333 MHz × 4 transfers/cycle = 10656MB/s。
前端总线的设计,使得CPU需要等待来自内存中的数据,对于每个元素需要的大量复杂计算的应用,这样的应用访存不是那么的密集,前端总线能跟上CPU的速度。而对于图像、音频、视频、游戏、FPGA综合以及科学应用等应用,通常是对于大工作集的少部分数据进行操作,这样前端总线就成为一个主要的性能瓶颈。
图16比较了2.0GHz的兆芯C4600、1.5GHz的龙芯3A3000、1.5GHz的AMD K10三款处理器访存带宽测试程序STREAM的带宽分值,从中可以看出,单线程STREAM的测试,C4600的STREAM带宽基本为4-5GB/s,而3A3000为8+GB/s,K10为6-7GB/s。多线程STREAM的测试,C4600的STREAM带宽基本为3+GB/s,而3A3000为12-13GB/s,K10位6+GB/s。
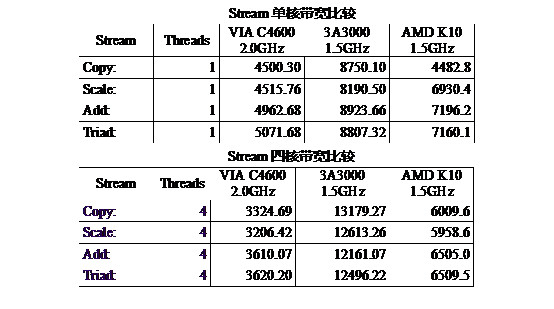
国际主流CPU都在十年前把内存控制器集成在CPU芯片中,而兆芯C4600继续把内存控制器集成在桥片上,访存带宽受限于前端总线。VIA 以赛亚系列处理器从2009年开始一直采用VIA V4 BUS的前端总线设计,而没有将内存控制器集成到芯片上,即使是2014年对Nano X2的改版也不愿意去动其结构和设计。只是从40nm工艺提高到28nm TSMC的工艺,同时把V4总线的频率从800MHZ提高到1333MHz,也就是其前端总线的理论带宽为10.6GB/s。所以其内存带宽不高原因也就可以解释。
另外,多线程的情况下,多个CPU核以及I/O等会竞争前端总线,前端总线和内存控制器的预期机制截然不同,造成访存序的紊乱。所以在多个线程尤其是访存压力很大的情况下,其性能会急剧下降。这也是C4600多线程带宽反而不如单线程带宽的原因。
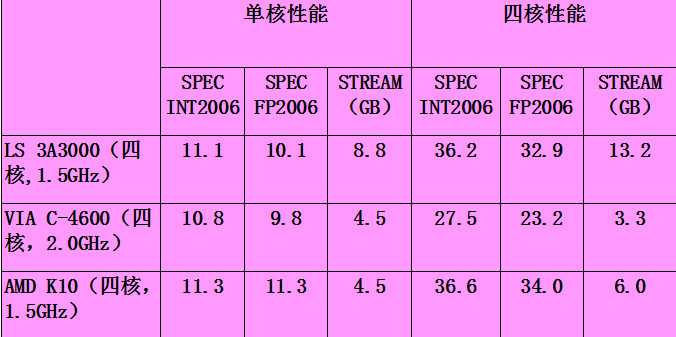
对于C4600,1-2个核基本上就吃满了访存带宽,对于龙芯3A3000而言,访存带宽具备显著的优势,其能满足4-8个处理器核的需求。所以,在单线程性能差距不大的情形下,龙芯3A3000的SPEC CPU2006多线程rate的性能,明显超过了C4600的rate性能。具体参数见图17
虽然在一系列兆芯官方宣传和中文宣传资料上,兆芯一直宣传自主安全可控(见图18),在其官方网站上也标明自主可控(见图19)。但与兆芯相关的英文材料却标明:Based on Centaur Technologie’s microarchitecture designs (见图20)。

在微结构源自Centaur公司,指令集授权也模糊不清的情况下,就宣布兆芯自主安全可控,未免有点超之过急——即便是走技术引进道路,也要在凭借自己的能力完成消化吸收再创新之后,才能称得上自主可控安全。比如在充分消化Centaur公司设计的以赛亚之后,凭借境内设计团队设计出可以匹敌Intel SNB或者AMD Zen的产品,这才真的称得上再创新。拿Centaur公司设计的以赛亚,改制程堆核心数提升总线频率做出一款CPU就宣传自主可控,无非是自欺欺人而已。
至于拿Centaur公司早年的设计,改头换面就成为国家“十二五”核高基重大科技专项创新成果,并能够荣获“第18届中国国际工业博览会金奖”(见图21)、“2017年度大中华IC设计成就奖”(见图22)、“第十一届(2016年度)中国半导体创新产品和技术奖”(见图23),也难怪国外资深IC设计工程师会对中国的IC设计水平嗤之以鼻了。




本站发布的Win10镜像与软件仅为个人测试使用,请在下载后24小时内删除,不得用于任何商业用途,请支持购买 微软原版 Msdn Win10 iso镜像!如侵犯到您的权益,请及时通知我们。
Copyright © 2019 u小马 版权所有 蜀ICP备20004165号-1
 川公网安备 51130402000044号
川公网安备 51130402000044号



